


In late October 2025, two of the world’s most powerful cloud platforms—AWS and Microsoft Azure—went down in spectacular fashion. Within just a week, millions of users and hundreds of global businesses were caught off guard as essential apps, services, and infrastructure ground to a halt. It was more than an inconvenience—it was a wake-up call.
If you’re an IT leader, CISO, or cloud strategist, now is the time to reevaluate your cloud stack, your resilience posture, and—most importantly—your assumptions. The stakes have changed.
The Hidden Cost of Hyperscale Cloud Outages
On October 19, AWS’s us-east-1 region—its most critical hub—was hit by a silent time bomb: a race condition in the DNS update system for DynamoDB. In plain terms, AWS accidentally wiped out the DNS record for a core service, and everything that relied on it began to fail. It wasn’t just DynamoDB. EC2 stopped launching instances. S3 buckets became unreachable. IAM stopped propagating changes. It took more than 15 hours to fully stabilize.
The week wasn’t over. On October 29, Azure stumbled with a global faceplant. A misconfigured update to Azure Front Door, Microsoft’s edge routing and CDN platform, propagated an invalid configuration that crippled traffic routing across the entire Azure network. Suddenly, Microsoft 365 services—including Outlook, Teams, and SharePoint—couldn’t authenticate. Xbox Live went dark. Even Heathrow Airport’s systems went offline.
These weren’t just technical incidents. They were business continuity failures—ones that exposed how deeply entangled enterprise operations have become with cloud service architectures.
Cloud Confidence Is Not a Strategy
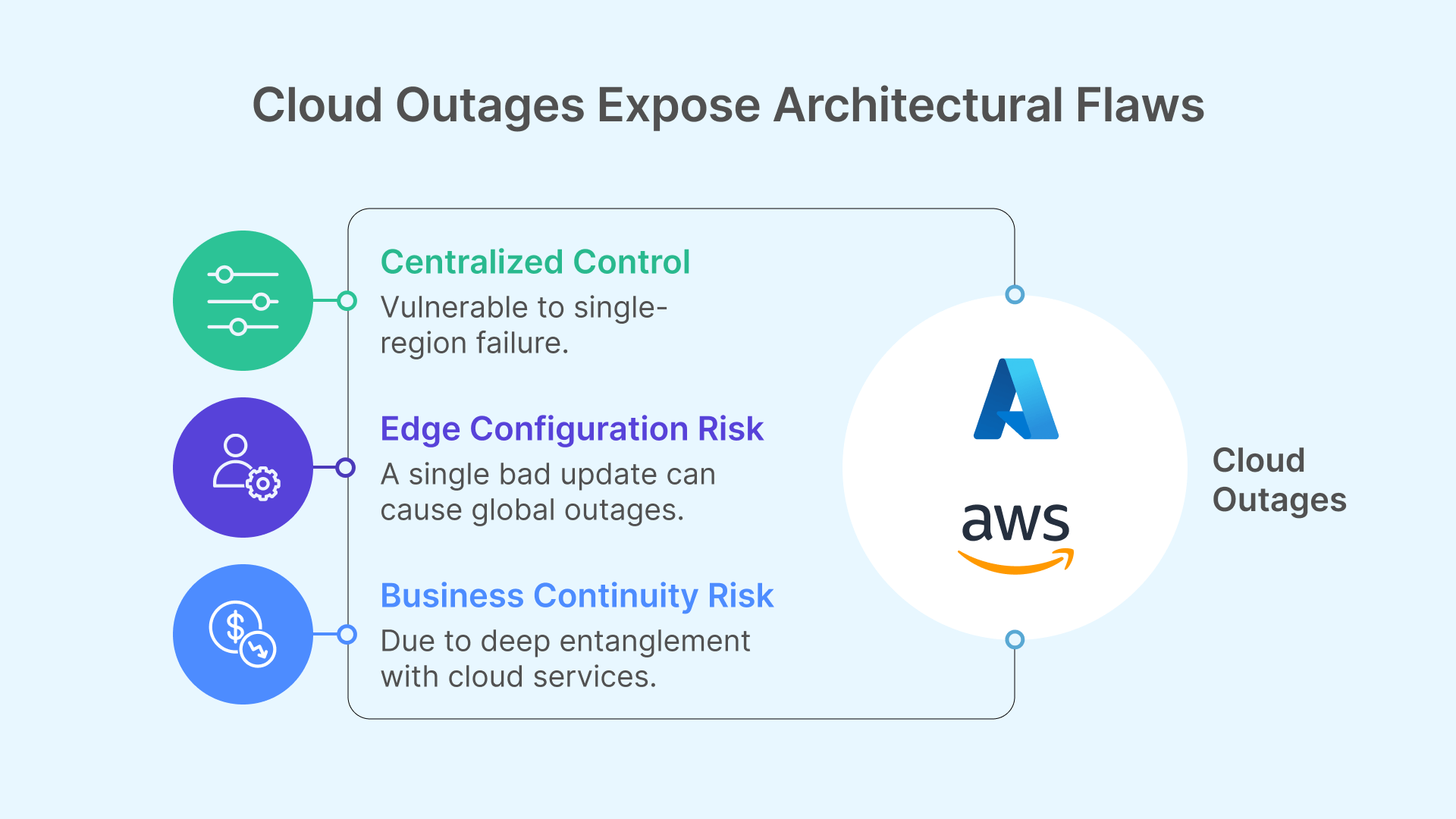
Both AWS and Azure offer world-class infrastructure, but their outages exposed architectural flaws that organizations can’t ignore:
- Centralized control planes: AWS’s heavy reliance on us-east-1 means a single-region failure can disrupt global operations.
- Edge-level configuration risks: Azure’s Front Door misfire revealed that a bad update to a single global component can bring down all regions simultaneously.
These weren’t exotic bugs—they were configuration issues and architectural assumptions gone wrong. The lesson? No matter how “enterprise-grade” your provider claims to be, complexity and centralization are enemies of resilience.
Why OCI Should Be in Every Enterprise’s Cloud Playbook
While Oracle Cloud Infrastructure (OCI) doesn’t always grab headlines, its design tells a different story—one that’s increasingly aligned with what enterprises actually need in a post-outage world.
Built for Resilience from the Ground Up
OCI treats each region as a fault-isolated domain. Unlike AWS, there’s no hidden dependency on a single master region. If one goes down, others keep operating—fully, autonomously, and without interruption.
And because OCI is built with a flat, non-blocking network fabric, it guarantees low-latency and high-throughput performance with minimal variability. That’s gold for latency-sensitive workloads like VDI.
Transparent, Predictable Pricing
OCI’s pricing model avoids the cloud creep and ambiguity of AWS and Azure. You get global flat-rate pricing, lower data egress fees, and no surprise charges—ideal for predictable VDI TCO.
Compliance-Ready and Globally Available
Need FedRAMP, HIPAA, GDPR, or local sovereignty for the EU or UK? OCI delivers. Oracle’s sovereign cloud offerings make it easier to stay compliant without the patchwork complexity of other platforms.
Thinfinity VDI on OCI: Modern Remote Access Without the Risk
Let’s talk solutions. Thinfinity VDI is a modern, browser-based virtual desktop platform designed for scalability, security, and flexibility. And when deployed on OCI, it becomes an incredibly resilient alternative to Amazon Workspaces, AppStream, or Azure Virtual Desktop (AVD).
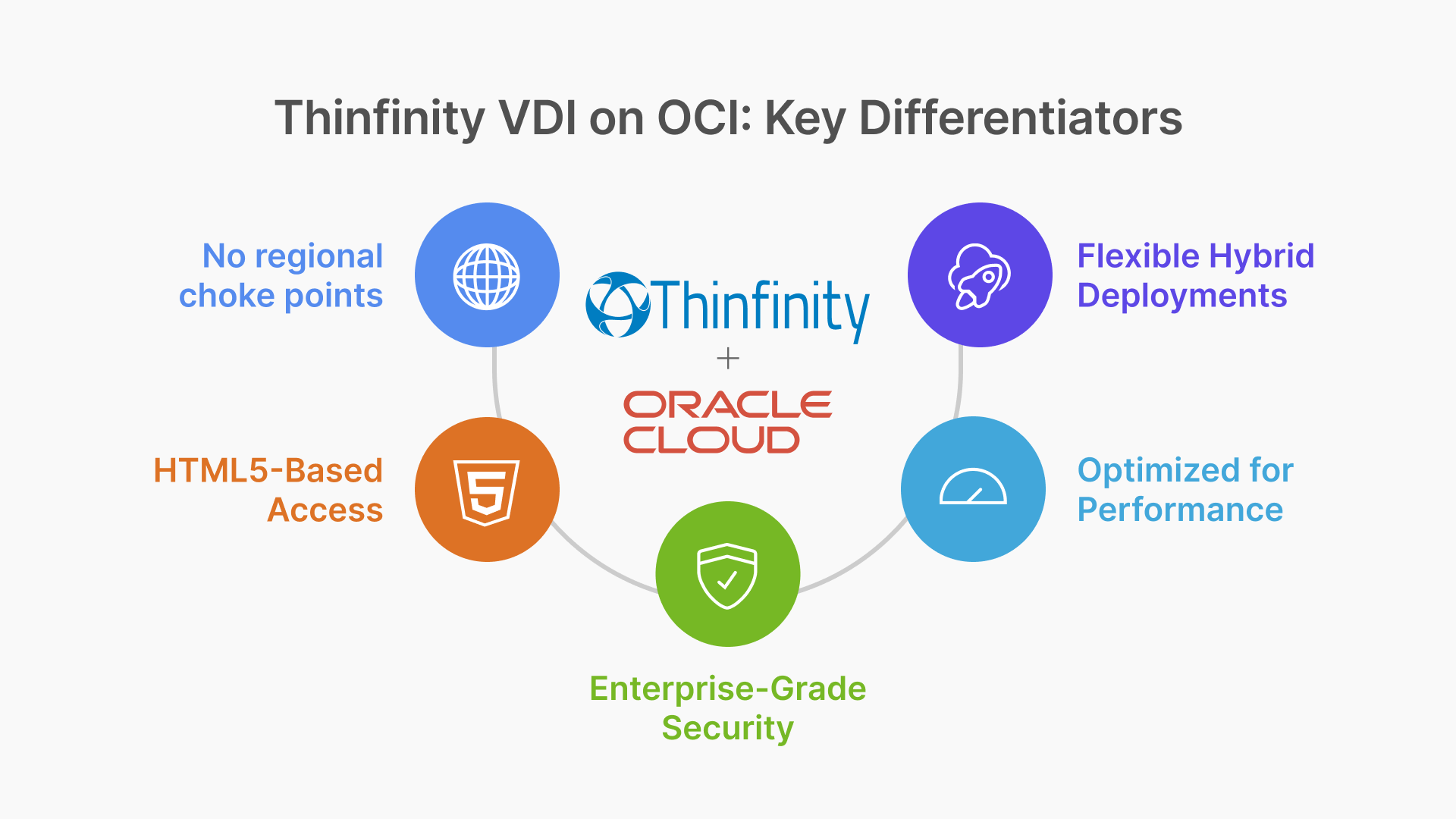
What Makes Thinfinity + OCI Different?
- No regional choke points: Unlike Workspaces or AVD, Thinfinity VDI instances can be deployed in isolated regions without dependency on centralized brokers or services.
- HTML5-based delivery: No client software, no VPNs. Just secure, fast access to desktops and apps from any device.
- Enterprise-grade security: Built-in MFA, SAML/SSO support, device posture checks, and full session auditing.
- Hardware acceleration: Leverage OCI’s GPU shapes for high-performance desktops (graphics design, CAD, trading floors).
- Hybrid- and edge-friendly: Thinfinity can live in both cloud and on-prem environments, letting you design for real-world needs, not just cloud-first fantasies.
By the Numbers: Why It Matters
According to Gartner, over 85% of cloud failures through 2025 will be due to customer misconfigurations and cloud architecture oversights—not underlying infrastructure issues. Yet, both the AWS and Azure outages of October 2025 demonstrate that even the best-managed platforms are still susceptible to internal errors that ripple across their customer base. The AWS DNS incident affected over 70% of the global traffic relying on us-east-1 region APIs, with Downdetector showing spikes in outages across over 1,000 apps. Meanwhile, the Azure Front Door misconfiguration caused global authentication failures for Microsoft 365, impacting an estimated 300 million active users worldwide for up to 8 hours. Enterprises that experienced downtime lost not only revenue but customer trust, with some e-commerce platforms reporting 20–30% daily sales drops during the affected window. These numbers aren’t just data points—they’re hard business costs.
The Story That Didn’t Make Headlines—But Should
While the world scrambled to understand the AWS and Azure failures, Oracle Cloud Infrastructure quietly stood firm. No cascading failures. No customer outages. No global headlines. In fact, OCI’s architecture—designed to isolate fault domains, avoid hidden control plane dependencies, and minimize network complexity—did exactly what cloud infrastructure is supposed to do: stay available. As a result, businesses already running latency-sensitive workloads, virtual desktops, or compliance-heavy applications on OCI experienced zero disruption. That’s not just a footnote—that’s a strategic differentiator. It’s time CIOs and CTOs stop treating OCI as a secondary option and recognize it as a front-runner for enterprise-grade reliability in a multi-cloud era.
What CIOs and CISOs Should Do Right Now
Don’t wait for the next outage to re-evaluate your cloud and desktop strategy. Here’s how to start:
- Audit your blast radius: How many services break if your primary cloud region fails? If the answer is “most,” you’ve got work to do.
- Design for failure: Use OCI’s isolated regions and fault domains to break dependencies and isolate failure domains.
- Evaluate alternatives: Test Thinfinity VDI on OCI as a secure, cost-effective alternative to your current solution.
- Embrace multi-cloud reality: Your future will not live on one cloud. Start building the foundations for portability and resilience.
Final Thought: Make Resilience Your Competitive Advantage
Every company wants agility, performance, and cost control—but the past few weeks have shown that resilience is what separates leaders from the rest. OCI and Thinfinity together offer a way forward: a VDI strategy that’s secure, scalable, and ready for whatever the cloud throws at you next.

