

A 2026 TCO guide comparing on-prem VDI vs cloud VDI for manufacturing—cost drivers, downtime economics, security overhead, and scaling across plants.
Introduction: Why “VDI TCO” Got Harder—and More Important—in 2026
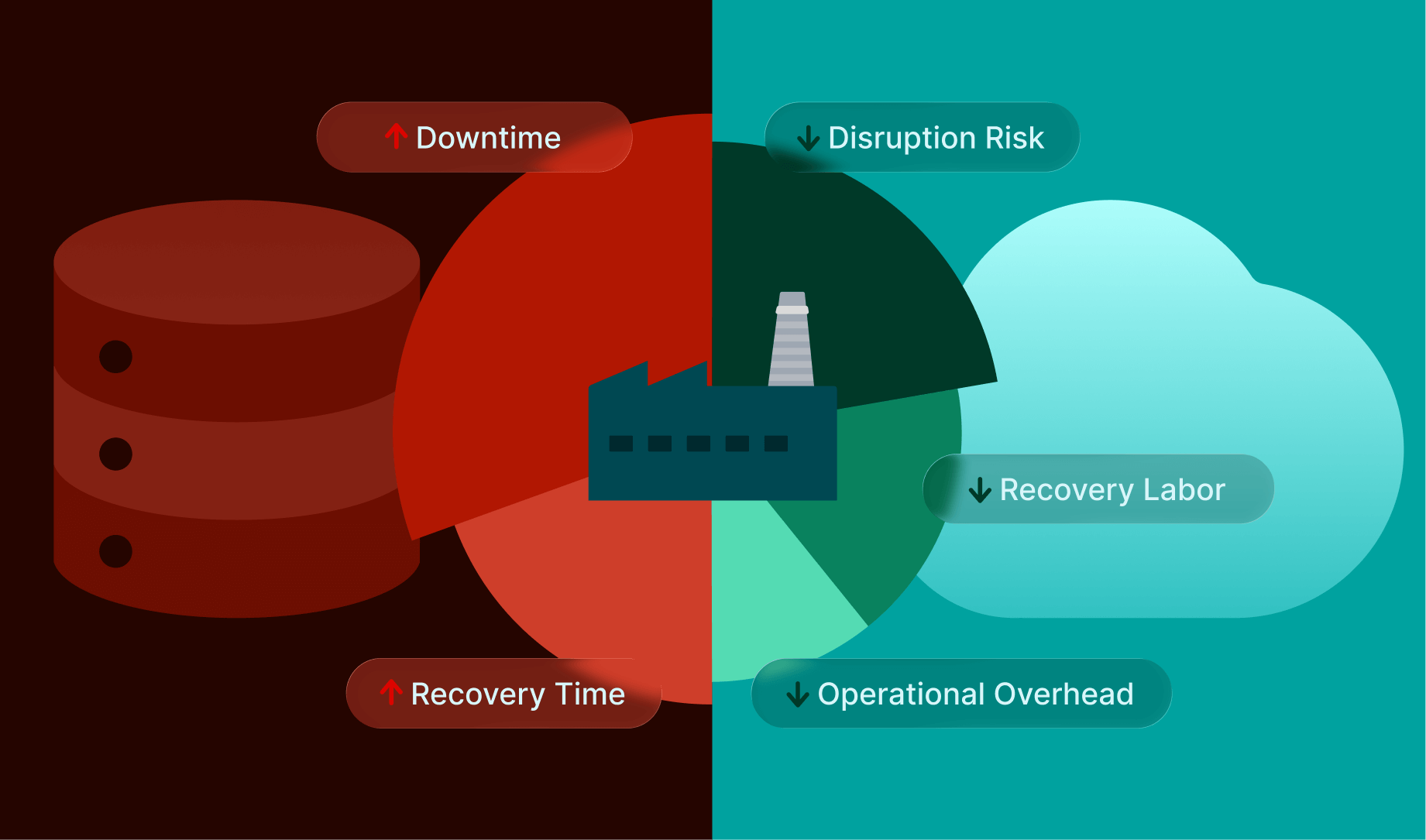
Manufacturing leaders rarely debate VDI in isolation. They debate it in the context of plant reliability, engineering throughput, OT/IT convergence, contractor access, and cyber resilience. In 2026, that context matters more than ever because the most expensive “VDI costs” often aren’t on the infrastructure invoice—they show up as downtime, recovery drag, and governance overhead.
Recent research keeps pointing to the same pattern: manufacturing continues to absorb outsized impact from ransomware and disruption. For example, research based on publicly reported incidents estimated $1.9M per day of downtime on average for manufacturing ransomware cases (2018–2024). And Kaspersky/VDC Research estimated that ransomware losses in manufacturing during the first three quarters of 2025 could have generated over $18B in losses. Sophos’ 2025 manufacturing-focused ransomware study also highlights how real-world recovery outcomes (time to restore, root causes, operational disruption) dominate the total impact.
That’s why a credible TCO comparison for manufacturing in 2026 must include three layers:
- Platform costs (compute, storage, licenses)
- Operational costs (support, patching, image governance, local IT load)
- Risk & disruption economics (downtime, recovery time, audit burden, security incidents)
This article gives you a practical framework to compare on-prem VDI and cloud VDI—and then narrows into how OCI changes the equation, followed by where Thinfinity typically fits.
What TCO Means for Manufacturing VDI
The manufacturing TCO definition that actually holds up
A usable TCO model is one you can defend to both a CFO and a plant operations leader. In manufacturing, that means translating “IT costs” into cost per productive hour and cost of disruption avoided.
A strong 3–5 year model usually includes these buckets:
- CapEx / committed spend
- Servers, storage, networking, GPUs
- Datacenter/plant room power & cooling (or allocation)
- Run costs
- VDI platform subscriptions/support
- Hypervisor/platform management
- Backup/DR tooling
- Operations & labor
- Central team + plant IT overhead (hands-on support)
- Image lifecycle, patching rings, change control
- Security operations (logging, investigations)
- Business impact costs
- Downtime hours (planned + unplanned)
- Recovery time after incidents
- Lost engineering throughput / delayed maintenance
- Audit and compliance effort for access traceability
If your model only compares “infrastructure + licenses,” it will systematically undercount the most expensive outcomes.
On-Prem VDI TCO in Manufacturing
Infrastructure sizing and the “per-plant headroom tax”
On-prem VDI in a multi-plant enterprise typically gets sized per site or per regional hub with enough headroom to handle:
- Shift peaks
- Seasonal labor spikes
- Engineering bursts
- Maintenance windows and hardware failures
That headroom is rational—plants can’t wait for procurement—but it has a cost: idle capacity you still pay for.
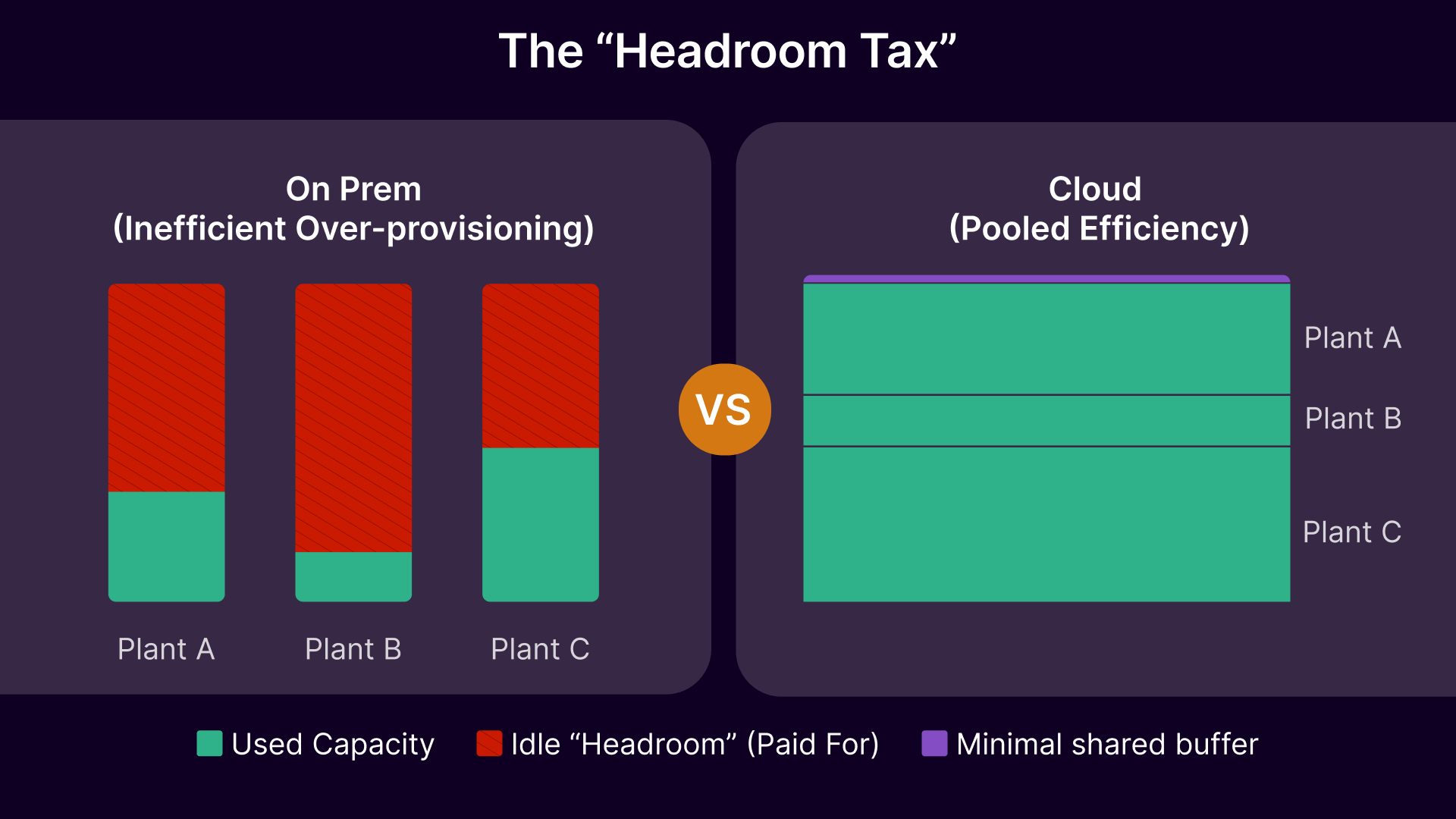
Common cost drivers:
- Refresh cycles every 3–5 years (compute, storage, sometimes GPUs)
- Redundancy requirements (N+1 / HA)
- Local spares and warranty coverage
- Dedicated facilities overhead (power/cooling allocation)
Operations costs multiply across plants
Manufacturing VDI failures are rarely clean and centralized. Even if the platform is “standard,” the reality is usually:
- Different network quality by site
- Different endpoint mixes (thin clients, rugged tablets, old PCs, kiosks)
- Different local constraints (maintenance windows, shift handoffs)
- Different exceptions (vendors, temporary access, shared stations)
That drives “hidden” TCO:
- Site-by-site troubleshooting
- Change control coordination across plants
- Drift in images/policies between locations
- Larger ticket volumes when local components fail
Downtime and incident recovery: the largest unpriced line item
Manufacturing downtime economics make TCO comparisons unforgiving. Even conservative public research has cited downtime costs in the millions per day for manufacturing ransomware disruptions.
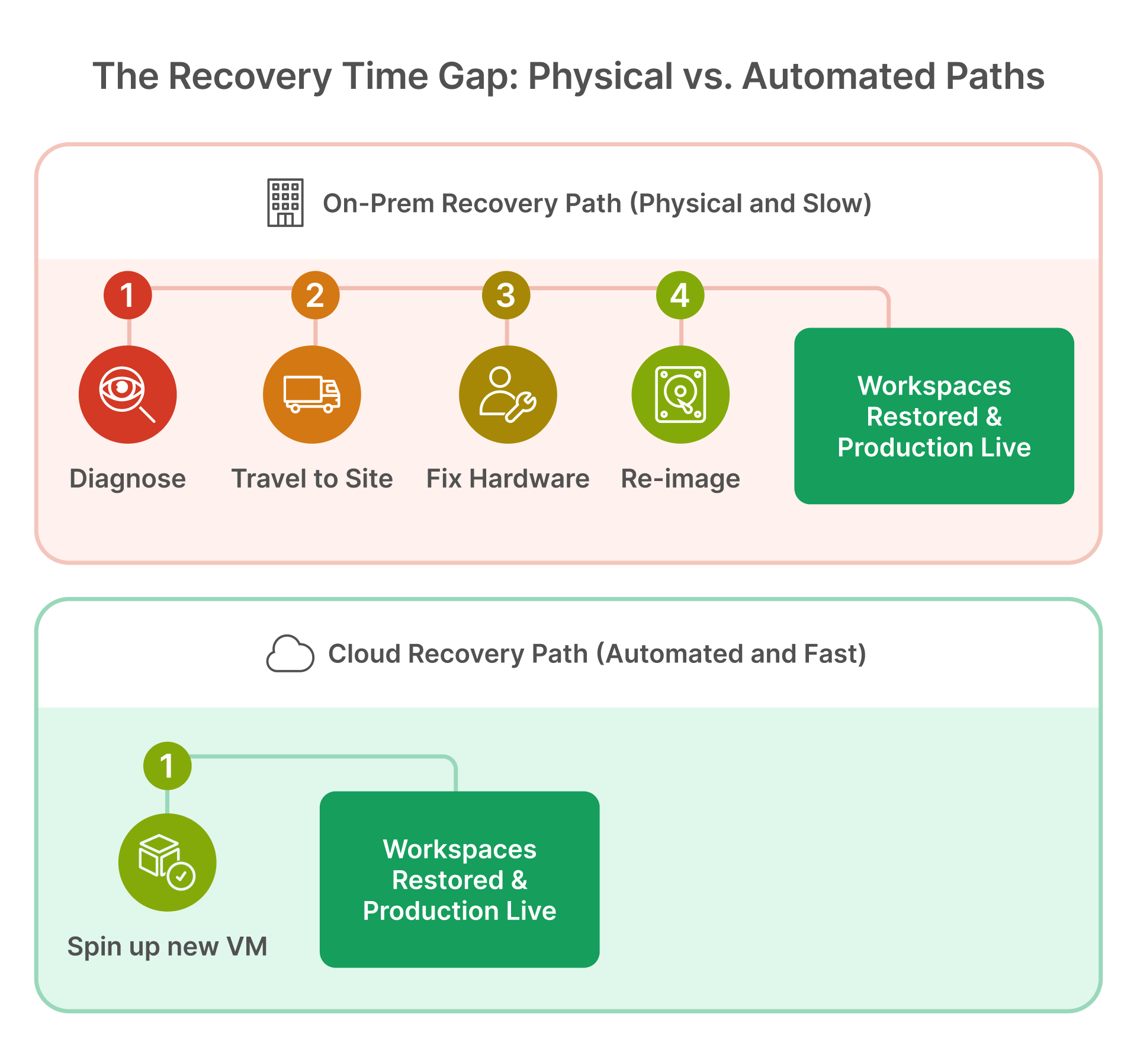
On-prem VDI doesn’t cause downtime—but it can make recovery slower when incidents hit local infrastructure, local identity systems, or when rebuilding requires site-specific steps.
In TCO terms, you should explicitly model:
- Average downtime incidents per year (IT + cyber + infrastructure)
- Mean time to restore workspace access for critical roles
- Number of endpoints requiring manual remediation vs pooled rebuild
Cloud VDI TCO in Manufacturing
Cloud changes the cost shape—not always the cost
Cloud VDI can be cheaper, similar, or more expensive on pure infrastructure, depending on how it’s designed and governed. What reliably changes is the shape of cost:
- More variable cost aligned to usage
- Less per-plant duplication of headroom
- More central control over images, patching, logging
This is also consistent with broader market movement: reporting on Gartner’s 2025 DaaS outlook emphasizes that net-new desktop virtualization is increasingly cloud-oriented and that TCO can compare favorably for many use cases, especially with thin clients.
The big cloud TCO levers: pooling, scheduling, and standardization
Cloud VDI becomes compelling in manufacturing when you can exploit:
- Pooling across plants (capacity shared across time zones/shifts)
- Scheduling (turn down nonproduction pools overnight/weekends)
- Standardization (fewer unique images and exception policies)
If you don’t apply those levers, cloud VDI can look like “on-prem costs, but metered.”
Security and compliance overhead can drop—if governance is designed in
In manufacturing, compliance is often less about a single regulation and more about demonstrating:
- controlled access to production-adjacent systems
- traceability of privileged actions
- consistent policy enforcement across sites and contractors
Cloud VDI can reduce the operational burden of audit readiness by centralizing logging and access enforcement—but only if you design for it (identity integration, standardized entitlements, consistent telemetry).
The Downtime Multiplier: A Practical Way to Compare Architectures
A simple model you can put in a spreadsheet
Instead of arguing “cloud vs on-prem,” compare expected annual disruption cost:
Expected Disruption Cost = (Incidents/year) × (Downtime hours/incident) × (Cost/hour) + Recovery labor
You don’t need perfect data; you need defensible ranges.
Recent industry reporting and research underscore that downtime in manufacturing can be enormously expensive—even outside cyber incidents. For example, UK-focused research cited high per-hour downtime impacts and frequent incidents, reinforcing why downtime dominates operational economics.
What to do with this model:
- Run it for critical roles only first (plant supervisors, maintenance leads, engineering)
- Compare how on-prem vs cloud affects downtime hours and recovery labor, not just platform cost
- Use ranges (best / expected / worst) to avoid false precision
OCI Focus: How OCI Influences Cloud VDI TCO for Manufacturing
(Here we narrow from general cloud VDI to OCI, since your series is manufacturing + OCI.)
Architecture repeatability reduces engineering and operations effort
In manufacturing, one of the biggest TCO killers is bespoke architecture per plant. OCI’s constructs (regions, availability domains, fault domains) make it easier to design repeatable templates for multi-site patterns.
This matters for TCO because repeatability reduces:
- time-to-deploy per new plant or new user group
- drift in network and security posture
- troubleshooting complexity
Availability design affects the true cost of outages
OCI documentation emphasizes high availability design using multiple availability domains (where available) and fault domains within an AD, reducing correlated failures.
For VDI, that translates into concrete TCO questions:
- Are connection brokers, gateways, identity dependencies, and profile stores architected to avoid single points of failure?
- Is your design resilient within-region and (if needed) across regions?
- What is the RTO for restoring “access to work” after an outage?
Even modest improvements in recovery time can dominate the cost comparison when downtime costs are high.
Performance + mixed workloads (office + OT-adjacent + engineering)
Manufacturing VDI is rarely one workload. It’s a portfolio:
- office productivity
- MES/quality access
- remote maintenance workstations
- engineering visualization / CAD for some groups
OCI’s published VDI + HPC reference architecture is relevant here because it addresses deploying VDI with performance-intensive patterns in OCI, which is a common manufacturing need when engineering and operations are part of the same program.
TCO implication: fewer “special-case platforms” can reduce operational complexity and vendor sprawl—but only if you standardize governance and image strategy.
Where Thinfinity Typically Fits in the TCO Model
Thinfinity usually shows up in manufacturing TCO analysis less as “a cheaper cloud” and more as a way to reduce integration and operational overhead across mixed environments.
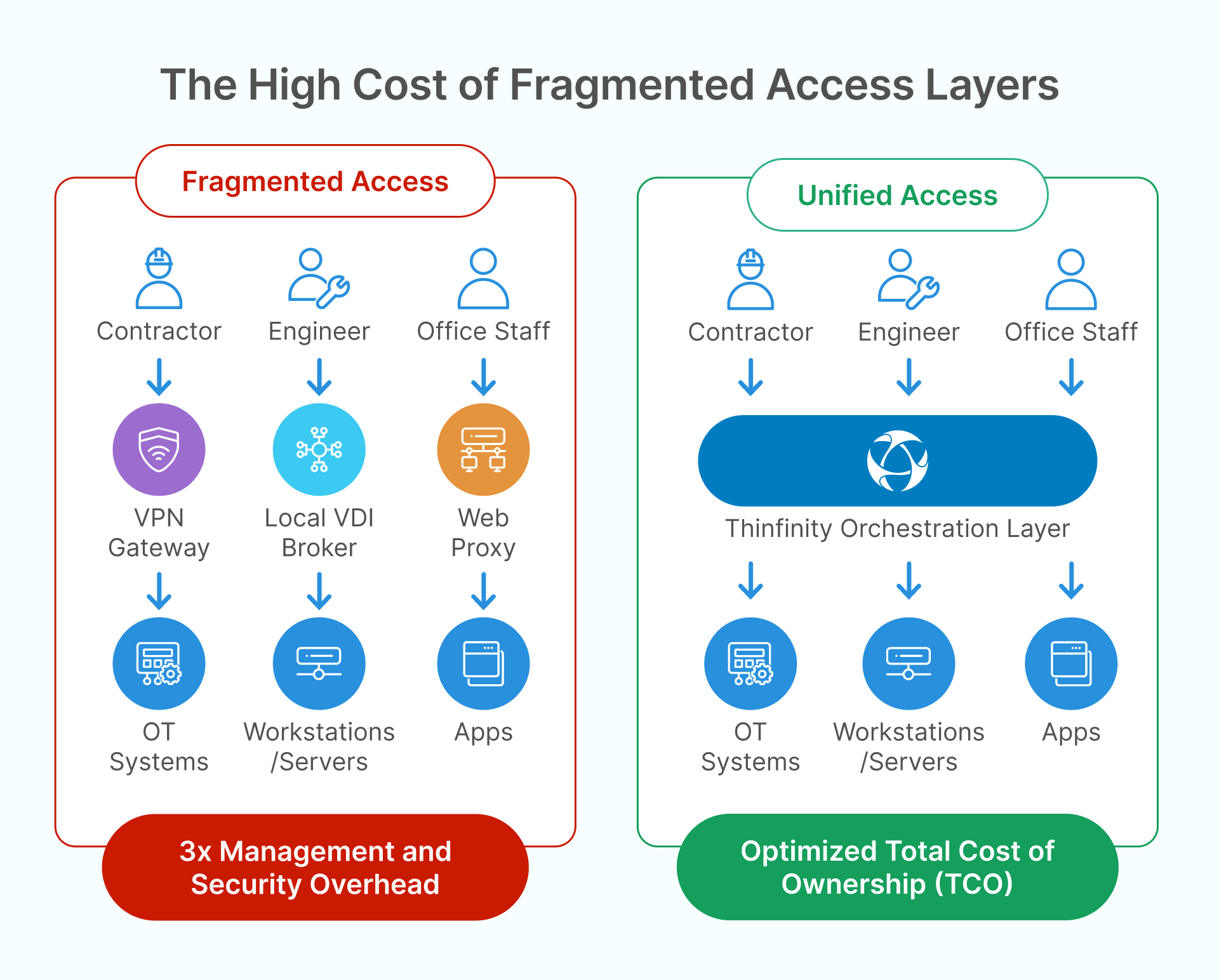
The cost levers it tends to influence
When organizations evaluate Thinfinity in this context, they’re often trying to reduce:
- Delivery complexity: fewer separate access methods for different app types
- Hybrid transition overhead: avoiding parallel stacks while plants migrate at different speeds
- Operational friction: standardizing how users connect, authenticate, and get authorized
- Time-to-onboard: contractors and vendors provisioned faster with consistent policy
In a TCO model, these show up as:
- lower labor hours per month for “desktop exceptions”
- fewer tickets related to access paths and client configuration
- faster onboarding/offboarding (risk reduction + time savings)
- simpler rollout patterns across plants
The main point: Thinfinity’s value in TCO terms is often about shrinking the ongoing cost of running the workspace, not just the cost of hosting it.
Conclusion: The Best Manufacturing VDI TCO Model Treats Workspaces as an Uptime System
In 2026, manufacturing VDI TCO isn’t a “cloud vs on-prem” debate. It’s an uptime economics debate.
If your environment has high disruption impact (and many do), the winning architecture is usually the one that:
- reduces downtime probability and shortens recovery time
- standardizes governance across plants and partners
- scales without multiplying operational overhead
- keeps security and audit readiness sustainable year-round
Cloud VDI can outperform on-prem in those dimensions, but only when it’s designed to exploit pooling, standardization, and resilience patterns. OCI’s architecture constructs and reference guidance can reduce design risk and support repeatable multi-site patterns. And Thinfinity is commonly evaluated as the orchestration layer that helps keep hybrid transitions and day-2 operations from becoming the hidden cost center.

